
引言
先看一组典型的 VOC 报表数据,这可能也是你每天都在看的:在好评榜里,“出色的音质” 占 48%;转眼看差评榜,“音质差” 赫然在列,占 31%。 再看核心属性,“舒适度” 既是 17% 用户赞赏的正向观点,又是 11% 用户抱怨的未满足需求。
这组数据到底告诉了你什么? 音质究竟是这个品类的护城河还是阿喀琉斯之踵?舒适度 “既好又坏”,产品经理该如何改款?
面对这种左右互搏的数据,你无法做决定。 这不是数据洞察,这是决策瘫痪。 这种扁平化的数据罗列,把最难的权衡工作原封不动地甩回给了卖家,而工具本该是帮你解决这个问题的。
上一篇文章 ,我们讨论了 “伪用户画像” 的问题 —— 关键词分析法难以还原真实的决策人。本篇,我们把目光转向评论分析的另一个核心目的: 用户需求分析 。你会发现,行业通用的分析方法论,正在产出同样具有迷惑性的结论。
评论依然是稀缺的 VOC,问题不在评论,而在 组织方式 。把评论整理成清单很容易;难的是解释矛盾、排出优先级,并把洞察翻译成可落地的动作。
传统方法:扁平化列表的迷惑性
目前行业里最流行的分析流派,是利用 NLP 技术对评论进行语义分析和关键词抽取,然后分成三类: 好评(正向观点)、差评(负向观点)、未被满足的需求 。最后,在每个类别内按提及频率排序。

这种方法表面看似客观严谨,但掩盖了两个致命缺陷。
问题一:正负观点经常自相矛盾,工具却不解释
“质量不错” vs “质量差”,“产品寿命长” vs “短暂寿命”。当正面和负面同时指向同一个属性,这往往不是噪音,而是 值得深挖的分化信号 :说明只有一部分场景或一部分用户出了问题。但 传统工具就此止步,只给出两个 “矛盾” 的百分比,却不告诉你到底是哪里存在分歧。
问题二:需求项目平铺罗列,无法判断优先级
在报表中,“有效遮阳面积”(功能性指标)占比 24%,而 “颜色美学”(审美指标)占比 14%。它们被并列展示。 但这两个需求的性质完全不同:前者是 “没有就退货” 的底线 ,后者是 “有了加分” 的锦上添花 。用同样的提及率去衡量它们,会让你误以为它们同等重要,从而导致资源错配。
为什么会这样?
上一篇我们讨论过关键词分析法的 “去语境化”。但在需求分析里,问题更进一步: 即使每个关键词本身准确,把它们扁平地堆在一起,仍然无法指导决策。 核心原因有两个:
核心盲区:不做分层
- 不区分用户分层 :高端产品用户抱怨 “质感廉价”,低价产品用户说 “物有所值”。不同人群,可能有完全不同的参照系与预期,如果不加以区分,混在一起统计就变成了互相矛盾的噪音。
- 不区分需求层级 :不同需求对用户决策的影响权重完全不同。有些需求是底线,有些是加分项,有些是惊喜。把它们平铺展示,等于把所有信息的价值压平。
把 “提及频率” 当成 “决策权重”
频率只是 “说得多”,不代表 “伤害最大”。有些低频问题会直接导致退货、一星甚至安全风险,必须优先处理;而有些高频抱怨顶多影响转化。只看百分比,会混淆需求的本质差异,容易把真正的 “致命伤” 淹没在热闹的词条里。
假设一家餐厅收到 100 条差评,其中 60 条抱怨 “等位时间长”,5 条抱怨 “食物变味”。如果只看频率,餐厅经理会优先解决等位问题。但 “食物变质” 是食品安全底线,一旦曝光就可能导致停业整顿、品牌崩塌。所以,那 5 条差评的杀伤力,远大于 60 条等位抱怨。
需求分析的逻辑是一样的: 频率是 “统计事实”,严重性才是 “决策依据”。
贝森洞察怎么做?
核心方法:以 JTBD 为指导,用 KANO 模型重构需求世界
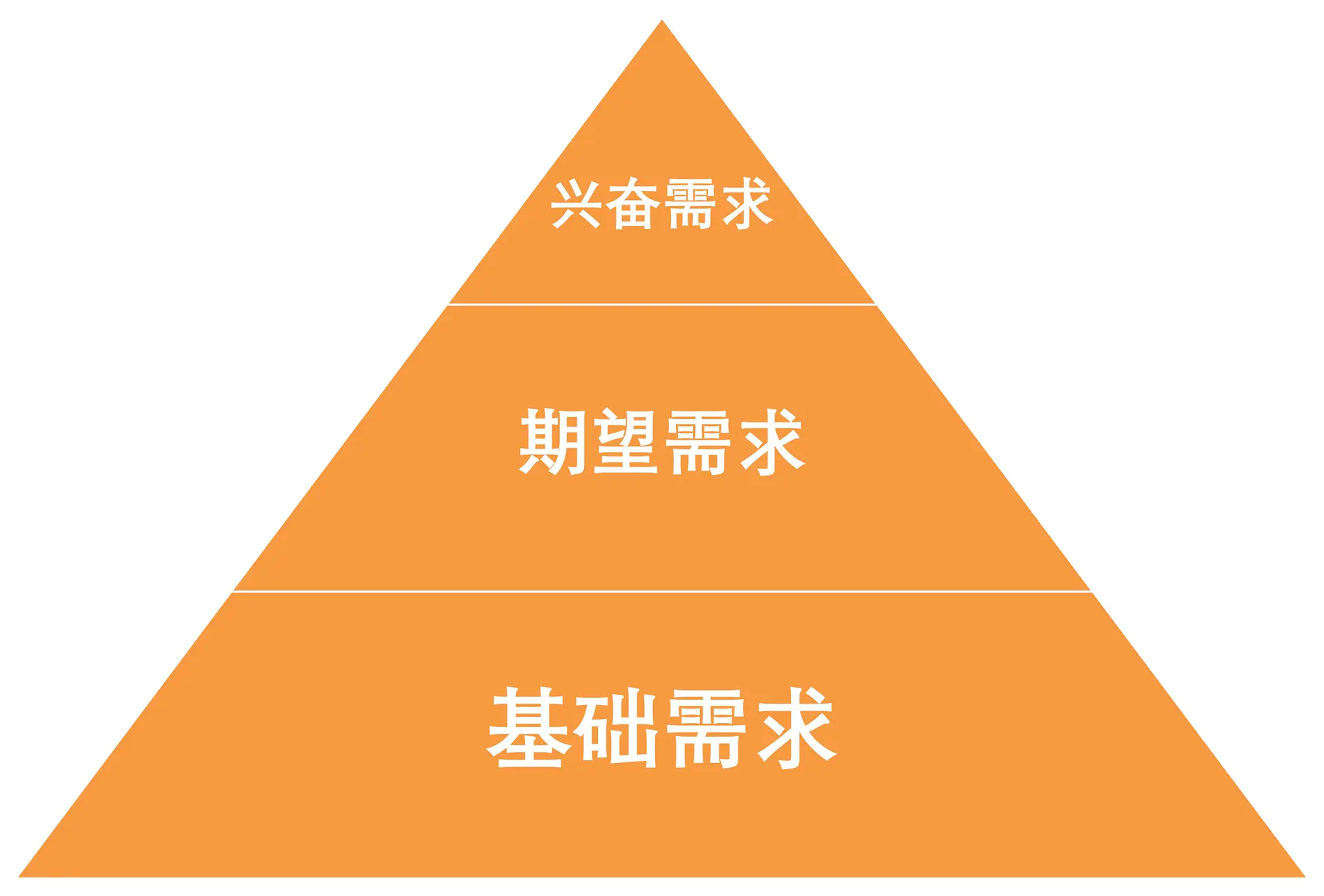
第一步:以 KANO 模型建立决策坐标系
贝森洞察不迷信 “词频统计”。我们使用 JTBD(Jobs To Be Done) 理论把评论放回 “决策现场”(情境、目标与权衡),并利用 KANO 模型 ,将扁平的关键词重构为有层级的需求结构。分层之后,你可以清晰地看到一张 “作战地图”:
| 需求层级 | 定义 | 缺失时用户反应 | 做好时用户反应 | 决策指导 |
|---|---|---|---|---|
| 基础需求 | 理所当然 | 愤怒、退货、差评 | 无感(不会专门表扬) | 必须做到的底线 |
| 期望需求 | 多多益善 | 不满、扣分 | 满意、加分 | 竞争差异化战场 |
| 兴奋需求 | 意外之喜 | 无感(本来就没有期待) | 惊喜、主动推荐 | 创新突破口 |
第二步:识别 “未满足需求”—— 寻找市场缝隙
这里需要特别说明的是:“未满足需求” 并非标准 KANO 模型中的第四个层级,而是一个横跨上述三个层级的 机会集合 。
它是我们在分析过程中识别出的、用户期待但尚未被市场充分满足的痛点或空白。它可能源自:
- 基础需求的塌陷: 例如产品宣称防水,实际上却漏水(基础需求未满足)。
- 期望需求的落差: 例如尺寸标注不明,导致覆盖面积小于预期(期望需求未满足)。
- 兴奋需求的空白: 例如市场全是丑陋的工业风,用户渴望设计美学(兴奋需求未满足)。
只有将这些机会点从 “好评 / 差评” 的混战中提炼出来,才能形成真正的产品开发指南。
实战对比:同样的评论,完全不同的结论
以 庭院遮阳帆 品类中的 “防水 / 排水” 争议为例(完整报告见 《亚马逊市场分析:庭院遮阳帆品类》),看看两种方法的巨大差异:
【传统方法的处理】
- 差评榜显示:“积水” 占比 12%;
- 未满足需求显示:“改善排水” 占比 12%;
- 卖家困惑: 既然都在骂积水,那我是不是该把帆布做透气?但好评里又有一堆人夸 “防水好”,到底听谁的?
【贝森洞察的处理】
首先,我们进行需求定性(KANO 分层):
- 基础需求(底线): “有效遮阳防晒”、“材质坚固”,这是核心,不能动。
- 期望需求(战场): “尺寸准确”、“安装便捷”,这是大部分竞争发生的区域。
- 兴奋需求(机会): “完美排水不积水”、“高级质感”,这是溢价来源。
然后,我们提炼 “未满足需求” 与行动策略: 我们不再罗列 “积水” 这个单词,而是深入归因,发现这实际上是一组 物理矛盾 :
- 痛点洞察: 用户想要防水(功能),但因产品缺乏合理的排水弧度设计,导致了积水(后果)。
- 行动建议: 你的决策不是在 “防水” 和 “透气” 里二选一,而是 做技术取舍 —— 如果坚持做防水款,就必须将 “优化排水曲率设计” 作为核心开发项,甚至在 Listing 中教育用户必须保持 30 度倾斜安装。
通过这种分析,原本矛盾的数据变成了清晰的 产品开发任务书 。
价值总结
同样是分析用户评论,不同的组织方式产出完全不同的决策价值:
| 核心维度 | 传统关键词统计 | 贝森洞察 KANO 决策模型 |
|---|---|---|
| 数据本质 | 扁平的单词列表 :只告诉你用户说了什么 | 立体的需求金字塔 :告诉你用户想要什么 |
| 面对矛盾 | 罗列冲突 :既显示产品寿命长,又显示产品寿命短,导致决策瘫痪 | 归因与取舍 :揭示物理矛盾,给出技术取舍建议 |
| 优先级 | 按提及率排序 :30% 的审美吐槽 > 5% 的功能失效 | 按决策权重分层 :5% 的 “基础需求” 缺失 > 30% 的 “兴奋需求” |
| 最终产出 | 一堆数据 :看完还是不知道怎么改 😡 | 行动指南 :补齐短板、优化提升还是差异突围,一目了然 😄 |
结语
回到文章开头的场景,如果你正在开发一款产品,面对 “安装简便 18% 好评” 和 “尺寸差异 16% 差评” 这组数据,你应该怎么决策?
答案现在很清晰了:
- “尺寸准确” 是基础需求 ,做不到用户会退货,这属于 “止血操作”,必须优先解决。
- “安装便捷” 是期望需求 ,做好了是加分项,属于 “优化操作”,优先级次之。
真正有价值的需求分析,不是告诉你 “用户既喜欢 X 又讨厌 X” 的废话,而是为你建立一套 决策坐标系 :知道哪条是生死线,哪条是进攻线,以及哪里是真正的机会点。
拒绝 “薛定谔的痛点”,从告别扁平化的关键词统计开始。
延伸阅读 : 为什么说大多数亚马逊评论分析得到的是伪用户画像?


